Empower energy users’ experience by embedding advanced subsurface data visualization with your data science in your digital solutions.
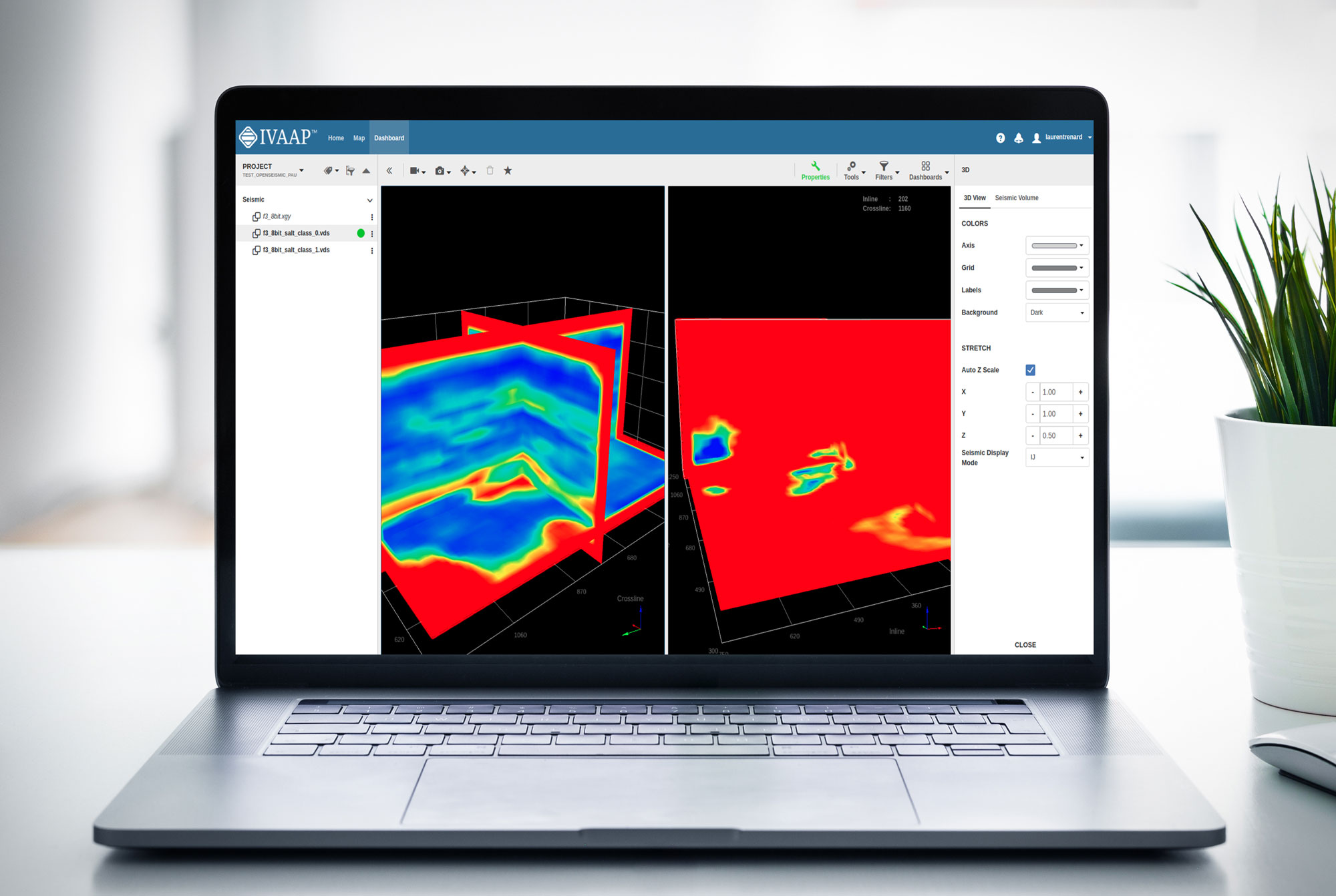
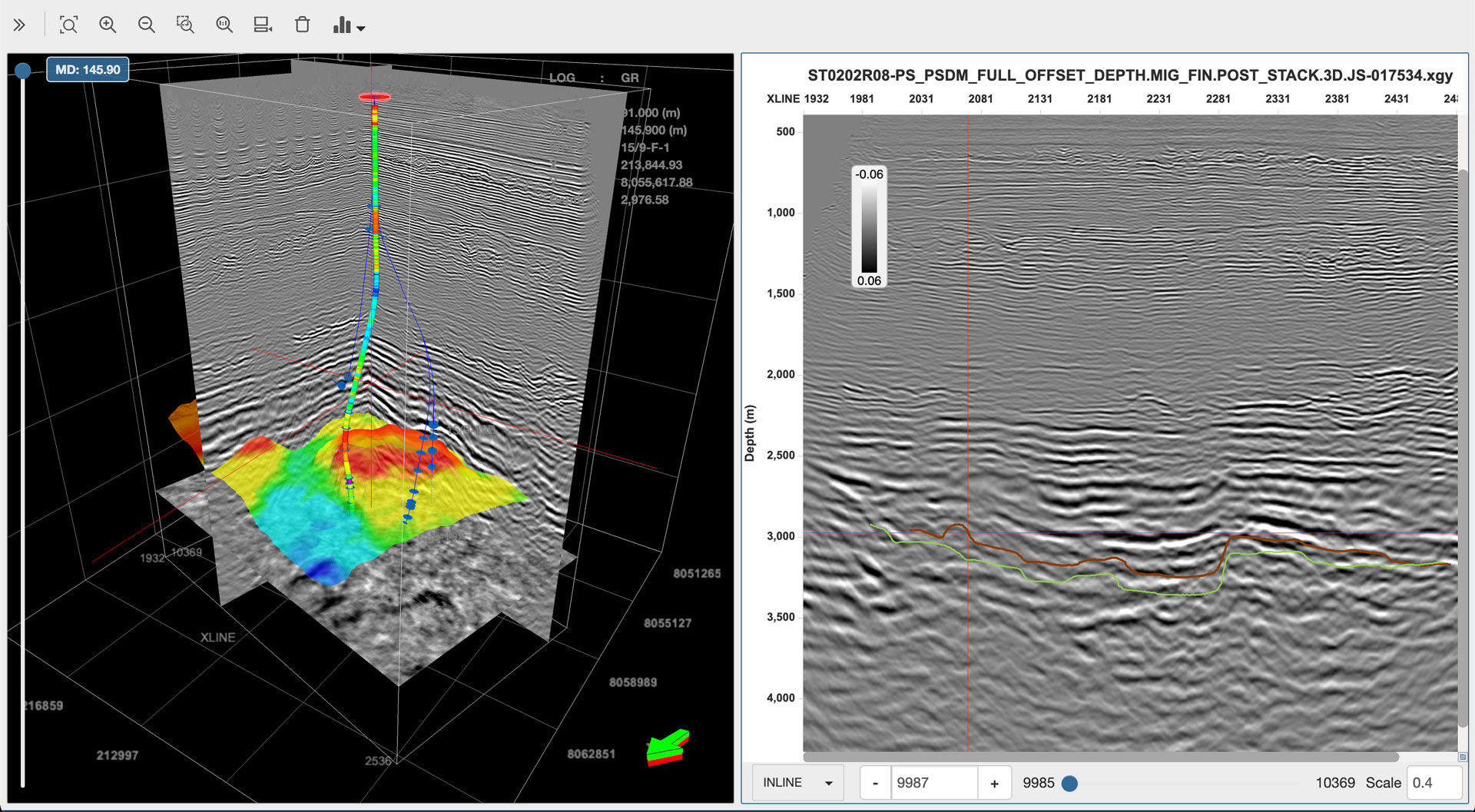
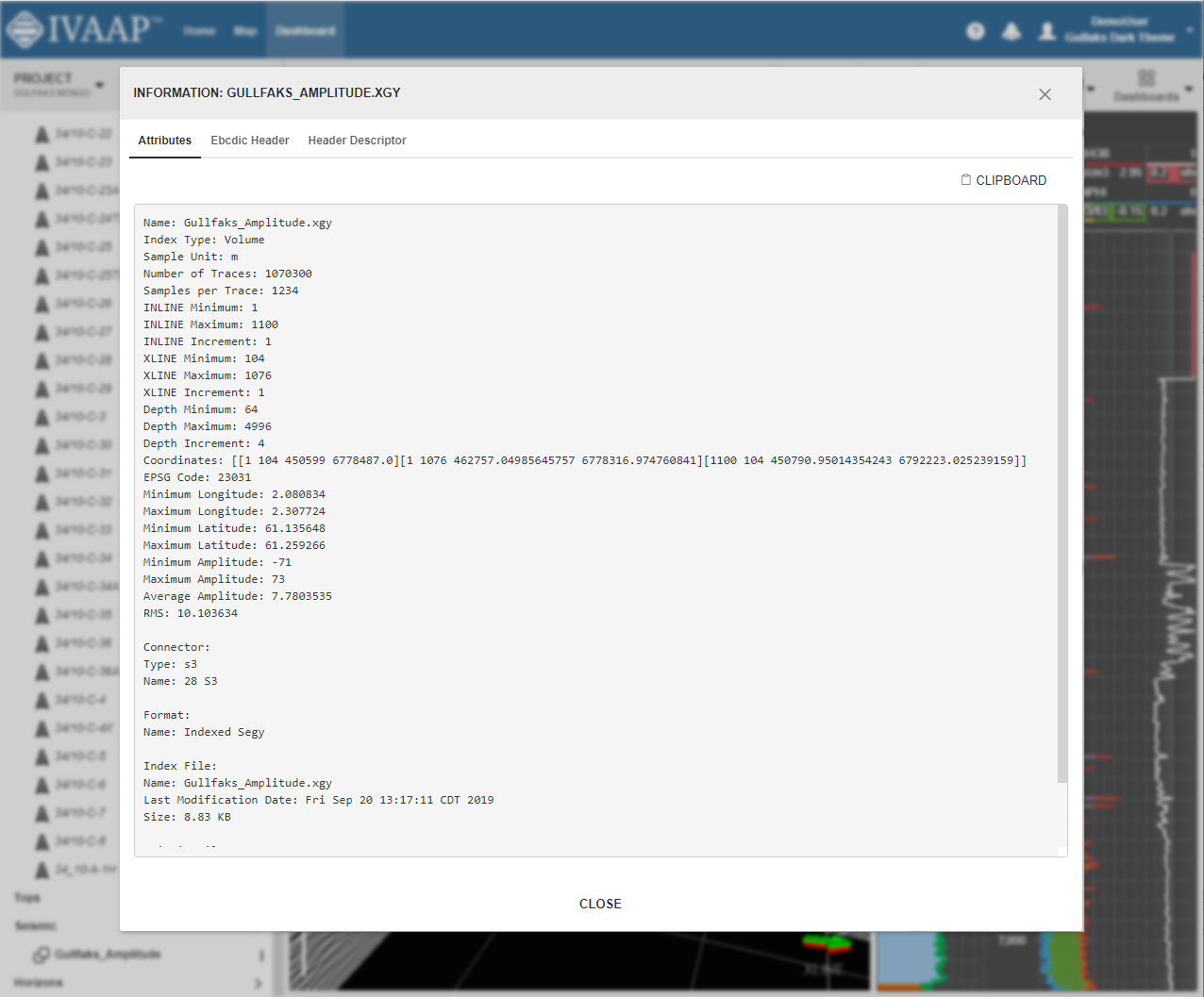
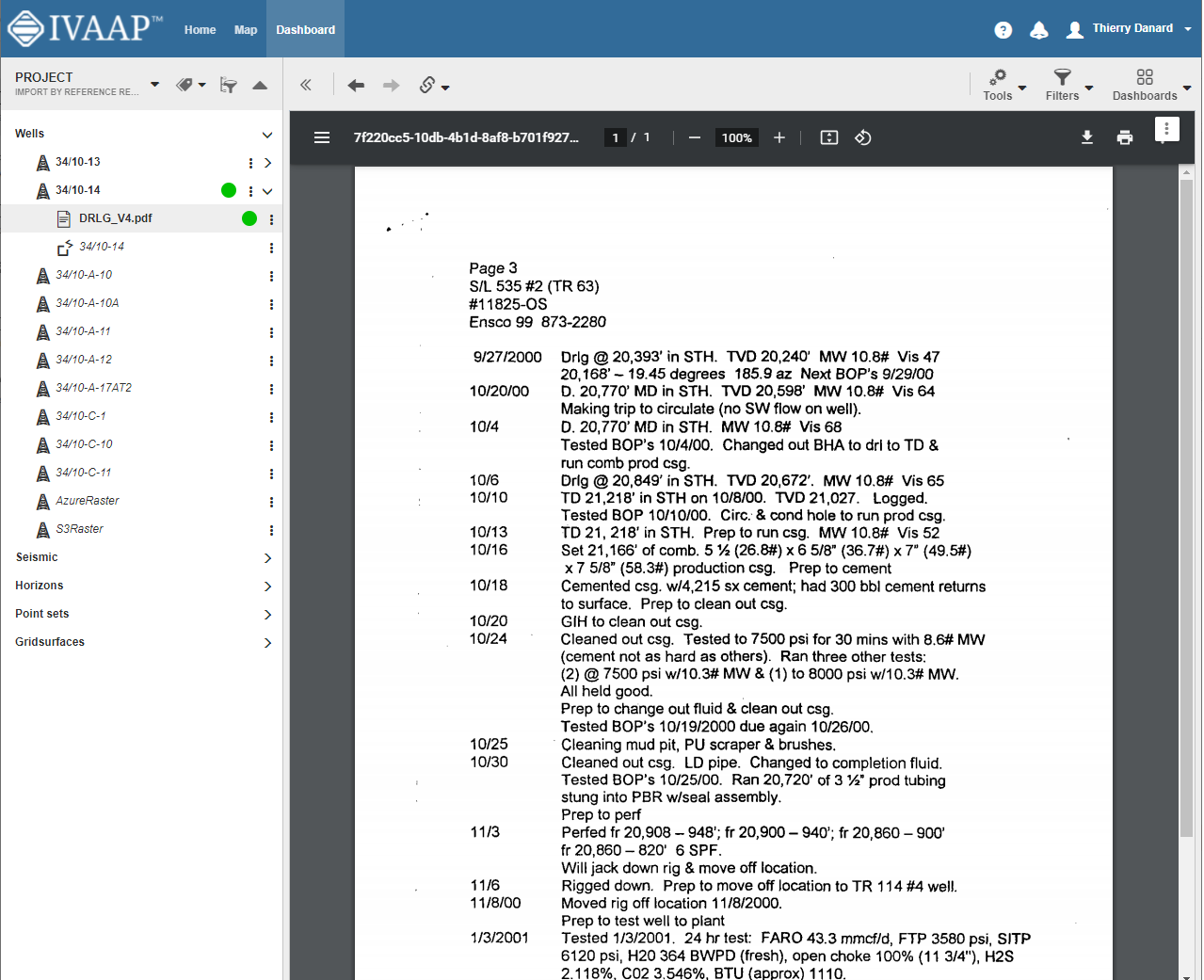
INT, a leading provider of data visualization software, just announced the newest version of their universal subsurface visualization and analytics application platform, IVAAP™. Offering full OSDU Data Platform support, IVAAP 2.9 enables exploration, visualization, and computation of energy data. The new release also expands IVAAP’s map-based search, data discovery, and data selection with 3D seismic volume intersection, 2D seismic overlays, reservoir, and basemap widgets to visualize all energy data types in the cloud.
As an OSDU-native application, IVAAP can accelerate the integration between the OSDU Data Platform and other EDM platforms. For example, INT recently partnered with Halliburton Landmark to demonstrate the power of interoperability between systems — linking IVAAP to Landmark EDM through the OSDU Data Platform on AWS.
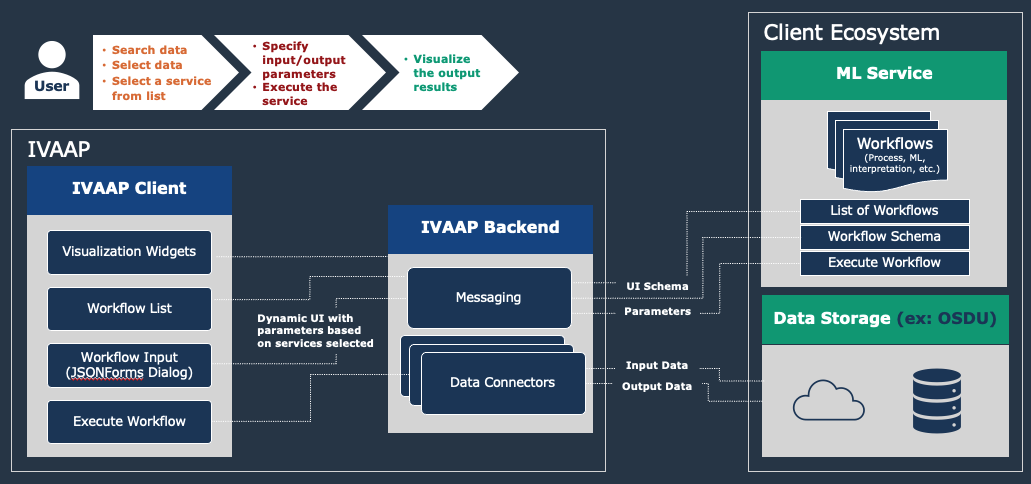
A major new feature of IVAAP is its integration capabilities with processing or machine learning services. This new capability was added in response to many energy companies who had many algorithms and models in various programs — Python, TensorFlow, Jupyter notebooks, to name a few — spread across the organization and were faced with the challenge to share them and make them accessible in other apps. With this new capability, IVAAP accelerates workflow integration and simplifies Machine Learning Operations (MLOps).
“We’ve been working to fully integrate new features in IVAAP that can streamline user workflows, reducing time to decision and empowering users with data visualization to help them to collaborate, make strong, accurate business decisions, and otherwise improve their ability to work with subsurface data for energy,” said Olivier Lhemann, president of INT. “With this release, we bring that full circle — users can now access their data using the power of the OSDU Data Platform, perform machine learning and processing models, and visualize the results.”
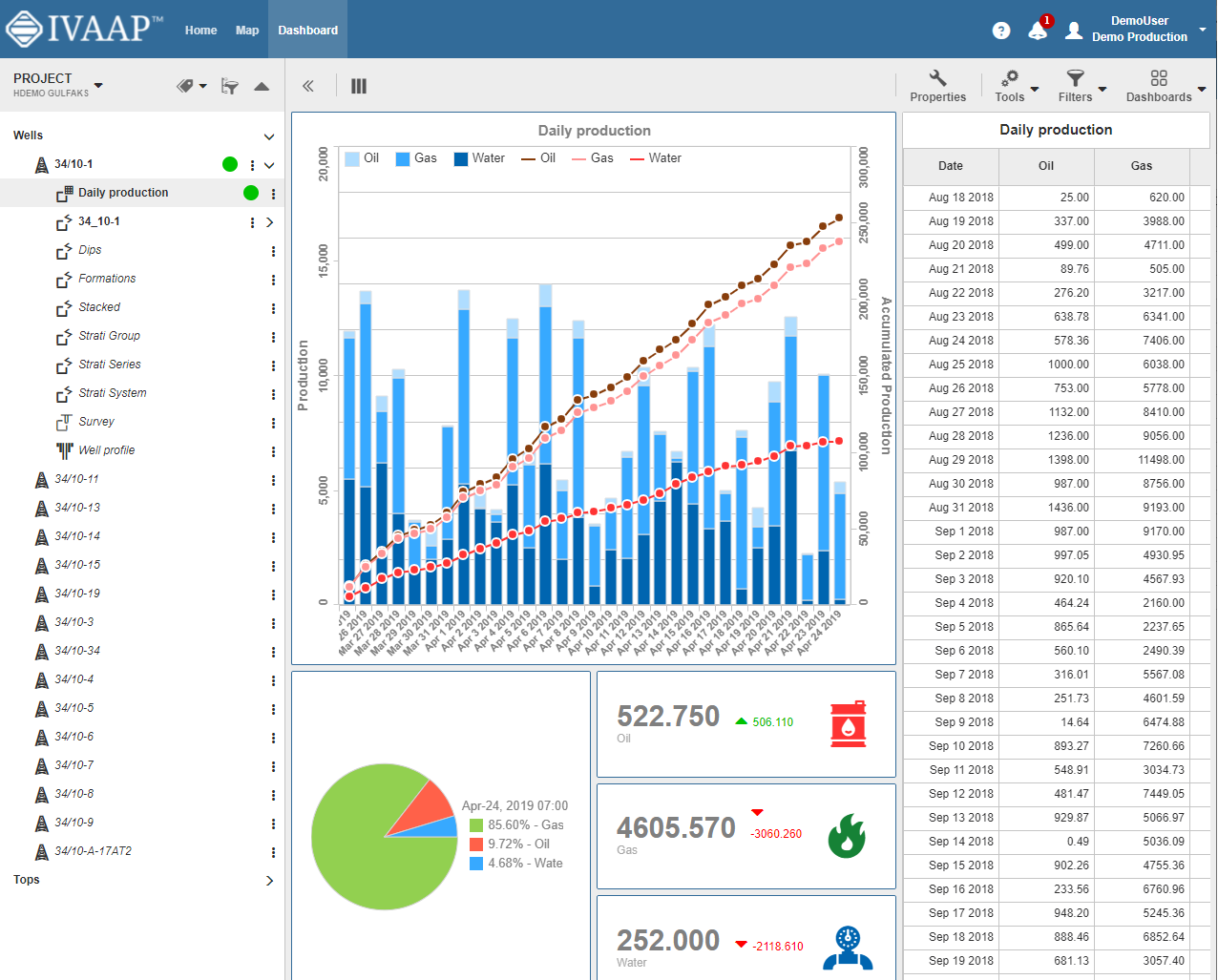
IVAAP’s workflow integration opens up a brand new user experience where now data scientists, modelers, geophysicists, and data managers can search data in the cloud, select data of interest, and launch computation from a single platform. IVAAP is providing new ways for operators, services, and energy technology software providers to enrich their digital solutions with powerful visualization and integration capabilities to OSDU Data Platform and machine learning for further automation.
Learn more about IVAAP at int.com/ivaap.
For more information, please visit www.int.com or contact us at intinfo@int.com.