When you are getting ready to embark on a multi-year journey of software development, technical design matters. You don’t just want to take into account the requirements of a minimum viable product, you have a roadmap for this product, and this roadmap gives you constraints. Over the years, a product evolves and so do the constraints. With the 2.11 release of IVAAP, now is a good time to revisit early technical design decisions for the IVAAP backends, decisions that have stood the test of time over the entire lifecycle of the product.
1. Designed to Mesh Data
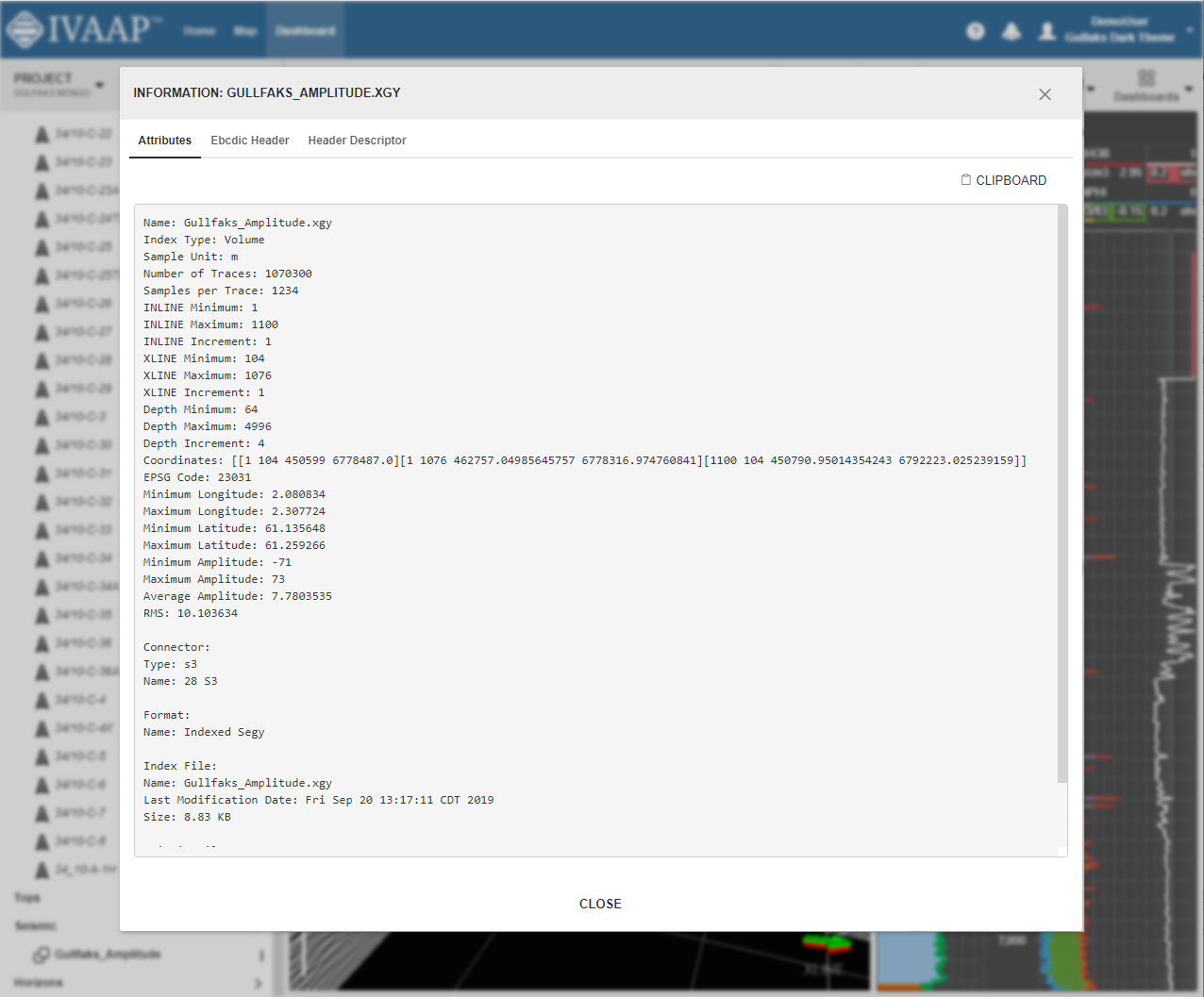
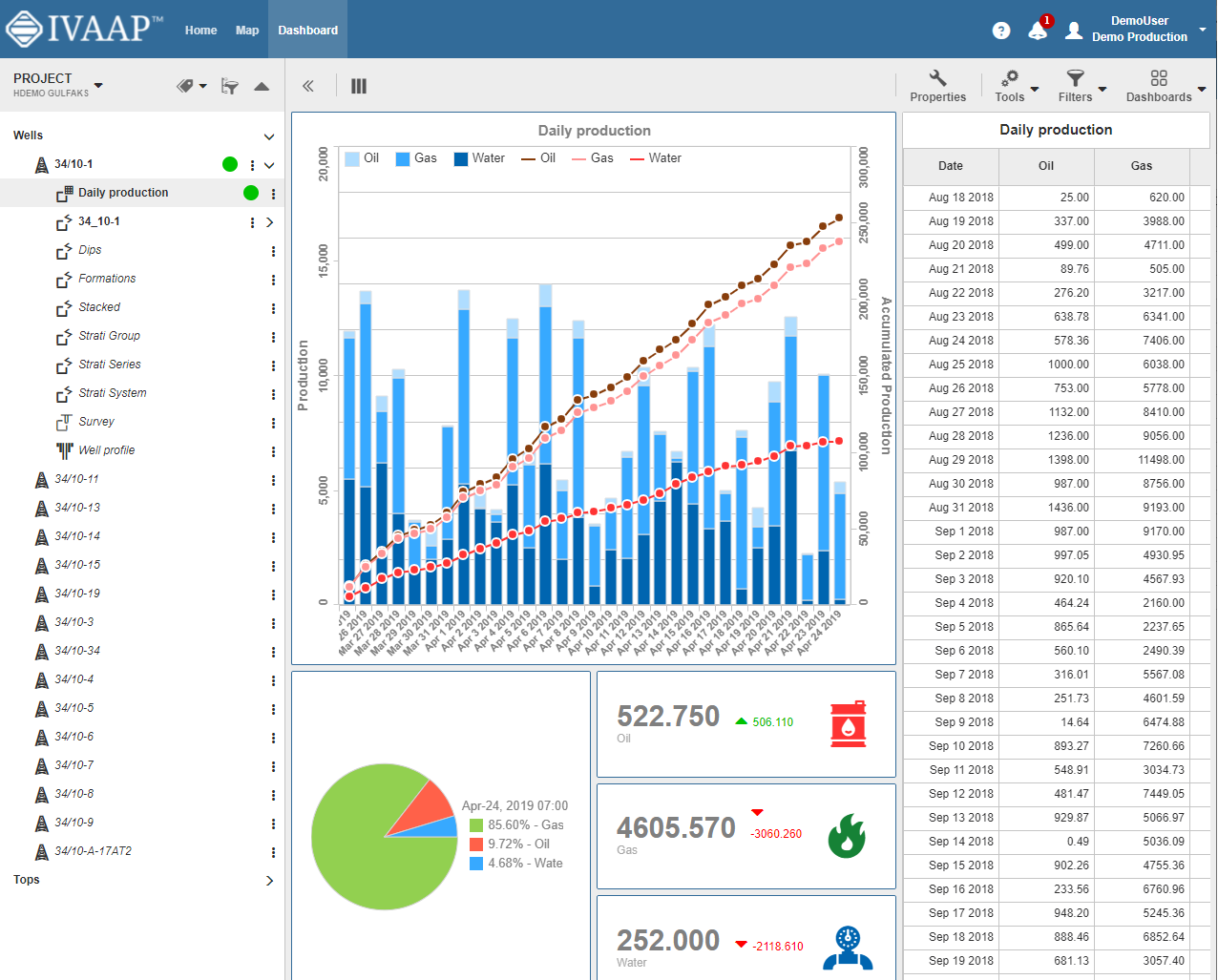
IVAAP has very strong visualization features. Some customers use IVAAP only to visualize data from their PPDM database, or from their OSDU deployment. Many others use IVAAP to visualize data coming from multiple data sources. This “multiple data sources” aspect of IVAAP has been part of the DNA of the product from the start. It gives users the ability to compare data across multiple systems, in one deployment, and in one consistent user interface.
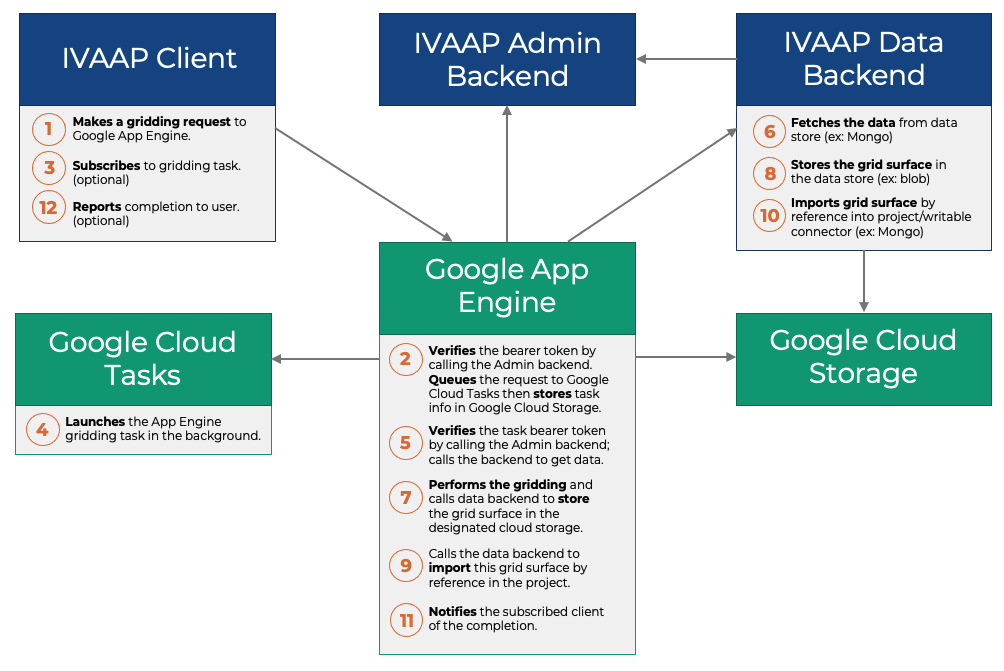
Technically, this feature imposes architectural constraints. First, from a reliability standpoint, when you access multiple data sources at the same time, you can’t assume all of them are available. And the failure of one data source shouldn’t affect access to data from another source. For example, if a PPDM database goes down, this shouldn’t affect access to WITSML data. This is one of the reasons why IVAAP has been designed as a “mesh” of multiple Java Virtual Machines. Even in the most basic deployment, each data source type (PPDM, WITSML, OSDU, etc) has its own dedicated sandbox, and it’s the role of the IVAAP cluster to make these sandboxes cooperate to give users a seamless experience.
Sandboxing access to each data source type also provides a simple way to scale. Whether the components of IVAAP are deployed with Kubernetes or with Docker Compose, you can customize at deployment time how each data source type scales.
The ability to access multiple data sources also permeates the way URLs are designed. The URLs of the IVAAP Data Backend are designed so that the cluster can easily route HTTP requests towards the right component. This routing doesn’t just affect the URL of REST services, but also the URL of real-time channels used in web sockets. These “mesh-friendly” URLs have stayed stable since the first version of IVAAP.
2. Container Agnostic
An architecture where multiple JVMs run in parallel is complex to deploy as a developer. 99% of the development time is spent on developing or modifying a service meant to execute within a single JVM. As a platform, IVAAP needed to be powerful, but also easy to use for the most common tasks. This is why it was designed to run on top of multiple containers.
The container used in production is made of a Play server and an Akka cluster. Each data source type is associated with a so-called “node” that is part of that cluster. The container used in development is an Apache Tomcat server, running Java Servlets. This is a configuration that most developers are already familiar with, and that IDEs support well.
From a code point of view, it makes no difference whether a service will be deployed in Tomcat or in Play. But being “container agnostic” goes beyond the benefits of seamlessly switching between development and runtime environments. The services written with the IVAAP Backend SDK may also be deployed on containers such as Amazon Beanstalk or Google App Engine. JUnit itself is considered a container, making it easy to unit test REST services without having to launch a HTTP server.
Introduced later, the Admin Backend benefited from the SDK’s versatility. While this SDK was initially designed with an Akka Cluster in mind, it is also used by the Admin Backend running Apache Tomcat.
IVAAP is a feature-rich platform, with hundreds of REST services. One of the reasons INT was able to implement so many services is the versatility of IVAAP’s SDK. Making abstraction of the underlying runtime environment was an early SDK decision, key to making IVAAP developers instantly productive.
3. Modular
When you develop microservices, there is one keyword that is the antithesis of the type of product you are creating: a monolithic application. To borrow from Wikipedia, “a monolithic application is a single unified software application which is self-contained and independent from other applications, but typically lacks flexibility.” A monolithic application is often used along proprietary data silos. From an architecture point of view, IVAAP is the opposite of a monolithic application — it attempts to free users from the proprietary data silos by providing the flexibility that silos lack. This is where a modular architecture helps.
With a modular architecture, optionalism is not limited to configuration, but also depends on the presence or absence of a module. From a development perspective, it is sometimes easier to develop and test a module that implements an option than to modify (and risk breaking) an already well-tested existing code.
Modularity is particularly useful when 99% of the product fits a customer needs, but the remaining 1% needs to be customized. With a modular architecture, the IVAAP code doesn’t need to be changed to implement a proprietary authentication mechanism. A custom authentication module can be deployed instead.
The benefits of modularity were well understood before INT started working on IVAAP. It’s really how it was implemented that turned out to have staying power. The IVAAP Backend SDK used a simple Lookup system to let developers plug or unplug implementations. This Lookup system was actually the first line of code I wrote when I started working on IVAAP. In a nutshell, a single annotation governs how classes are registered into the lookup at startup. It’s an API that is incredibly powerful, but also simple to learn. The entire IVAAP Backend code was built around it.
4. Developer-Friendly Data Models
IVAAP supports multiple types of data sources. Many of these data sources contain well data, but they all have their own way of storing that data. The role of a connector’s implementation is to expose this data to the rest of IVAAP, using a standard data API.
A typical way to do this is to use the concept of “Data Access Object.” To quote Wikipedia again, “a data access object (DAO) is a pattern that provides an abstract interface to some type of database or other persistence mechanism.” The IVAAP SDK follows this DAO concept, but while keeping developers in mind.
A typical DAO implementation indicates which interfaces need to be implemented. A developer working on a connector would code towards these interfaces, then start testing the code. This approach has several problems. One of them is that a developer cannot start testing his/her work until all interfaces have been implemented. The second problem is that there may be lots of interfaces to implement, delaying further the availability of the work.
IVAAP’s DAO approach introduces the concept of “finders” and “updaters.” Finders are in charge of performing “read-only” data accesses, while “updaters” are in charge of updating this data if needed. Finders and updaters are added to the lookup at startup. Unlike a classic DAO implementation, developers only need to plug finders and updaters that will be actually used, that actually match data in the data source they are working with.
For example, a WITSML store may contain “well risk” data and INT’s WITSML connector implements a “well risk finder.” A PPDM database doesn’t contain “well risk” data and INT’s PPDM connector doesn’t need to implement a “well risk finder.” By splitting the code requirements into fine-grained finders and updaters, the IVAAP SDK implements a DAO system that requires only the minimum amount of code for developers to write.
Paired with well-defined data models, the now battle-tested concept of finders and updaters has been a key element for new developers to learn the IVAAP SDK and develop connectors fast.
5. Circle of Trust
Going back to the idea of a “monolith,” one of the pitfalls of building a monolith is that a monolithic application can often only talk to itself. Since IVAAP is based on microservices, it is, by design, a system that is easy to integrate with. There is however a constant hurdle to such integration: authentication and security.
When authentication is simple, many systems use the concept of a “service account” to consume microservices. But “service accounts” often break when multi-factor authentication is required. When integration with other systems is a concern, we found that microservices need to be able to clearly differentiate human interaction from automated interactions.
This is essentially the purpose of the Circle of Trust. When deploying IVAAP, the software components that require special access can authenticate themselves as such. For example, a Python or Shell script that scoops up the monthly activity report would identify itself as a member of the Circle of Trust to access this report.
As IVAAP matures, many of the solutions proposed today by INT to its customers involve the Circle of Trust. The Circle of Trust is a simple but secure way of integrating third-party software with IVAAP. While it is a recent introduction to IVAAP’s design, it has become a key tool to meet customer needs.
Conclusion
The designs above made IVAAP’s journey possible, but IVAAP’s journey is not over. What they all share is a focus on users. Whether these users are geoscientists or programmers, these designs were meant to empower them. Empowering doesn’t just mean catering to today’s needs — it also means anticipating tomorrow’s requirements and making them possible. These five designs were strong enough that they were the gifts that kept on giving.
Visit us online at int.com/ivaap for a preview of IVAAP or for a demo of INT’s other data visualization products.
For more information, please visit www.int.com or contact us at intinfo@int.com.