IVAAP on OSDU R2 supports seismic visualization, data aggregation with unparalleled performance in the cloud to serve large seismic volumes using IVAAP’s HTML5 technology combined with OpenVDS format.
HOUSTON, TX — May 21, 2020—Interactive Network Technologies, Inc. (INT), a leader in advanced HTML5 domain visualization in oil and gas, is pleased to announce their contribution to the new release of The Open Group’s Open Subsurface Data Universe™ (OSDU) Data Platform Release 2.
The OSDU R2 release integrates INT’s robust seismic visualization capabilities and Bluware’s open source Volume Data Store (OpenVDS). Additionally, INT contributed a Java-native interface wrapper to support the adoption of OSDU across the industry. OpenVDS and IVAAP™ work together to support fast rendering of large seismic dataset in the cloud in 2D and 3D views.
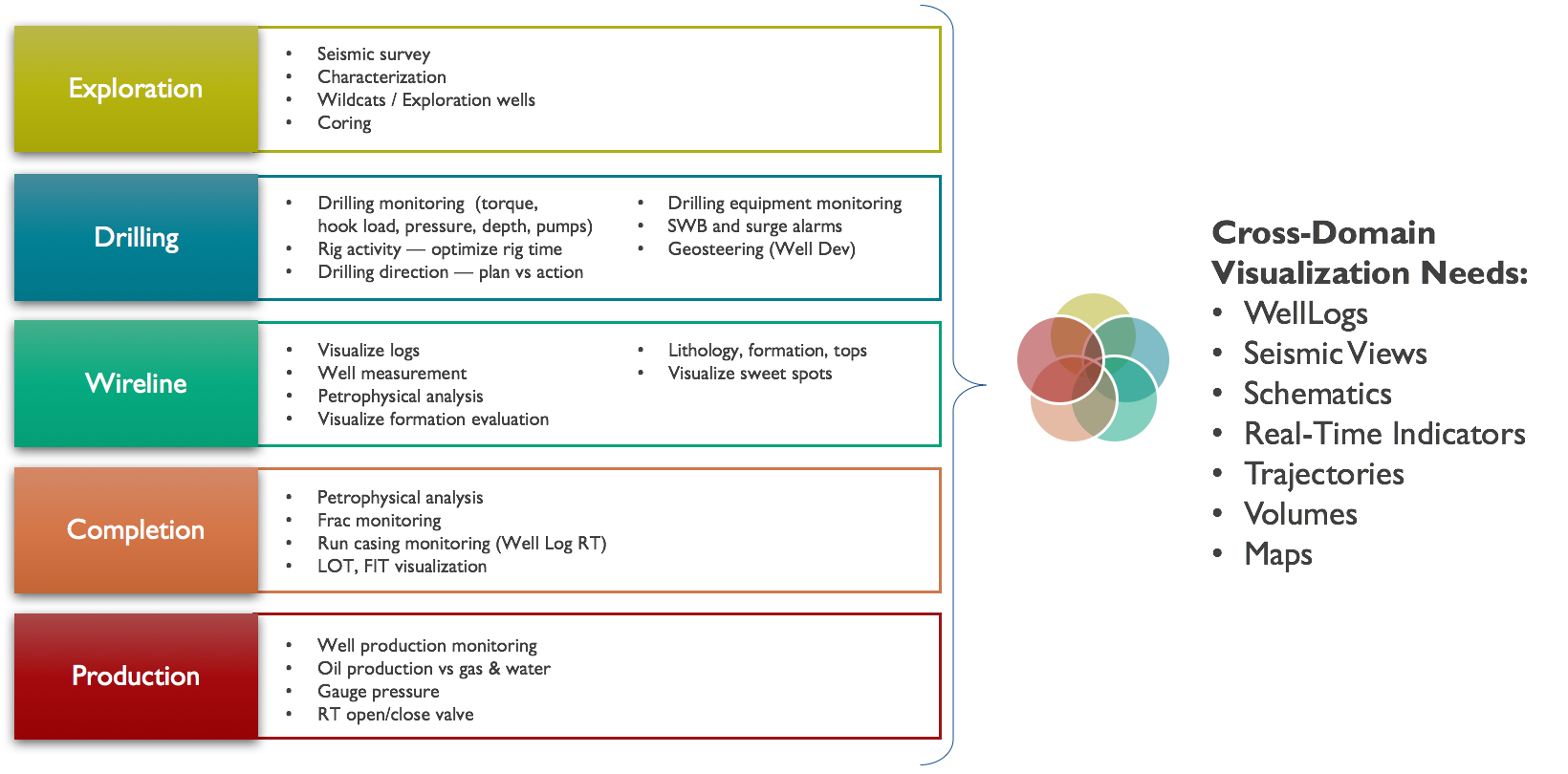
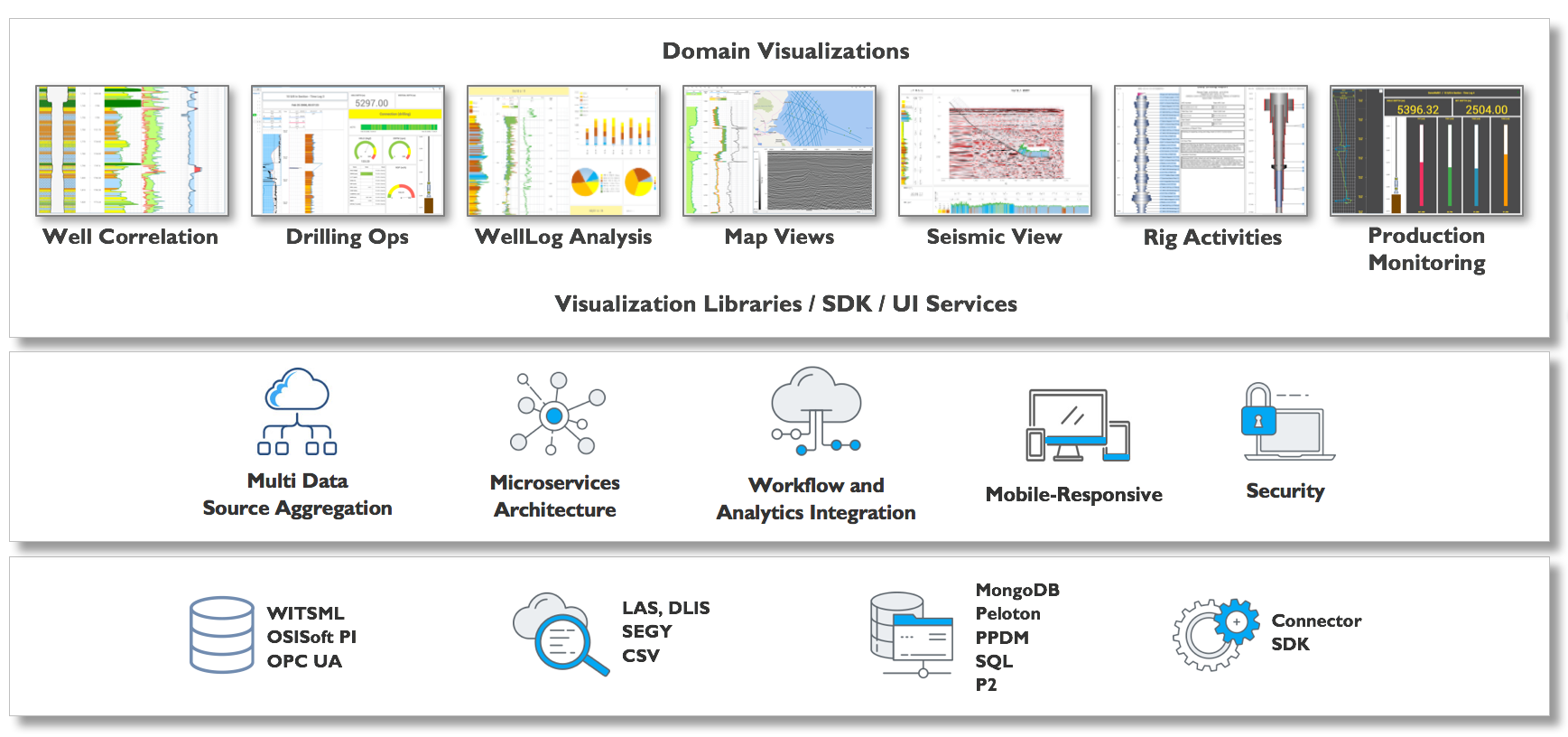
INT’s enterprise upstream visualization platform, IVAAP, enables full data aggregation and visualization of domain data across multiple cloud platforms and data storage. Using a microservices architecture, IVAAP supports most industry data standards, including OSDU, PPDM, WITSML, and several commercial databases, and enables user co-visualization. IVAAP’s unique dashboard capabilities combine data types—real-time, historical, 2D/3D seismic, reservoir, and more—to provide a unified view of exploration, drilling, and production operations in a web browser.
INT collaborates closely with the OpenSDU team to help validate the platform and create a powerful framework that developers can embed to deliver cloud-based digital solutions much faster than ever. Using the powerful OSDU search and delivery API, IVAAP allows users to search, find, display, and analyze data on the fly, including log, trajectories, tops, seismic, horizon and fault data.
Creating a common environment hosted in the cloud enables oil and gas companies to efficiently access massive amounts of data, reduce data silos, collaborate remotely, implement machine learning (ML), and lower the cost of operations.
“Working closely with The Open Group, IVAAP made it possible for users to visualize seismic data. We are very proud of the work the team—including our partner Bluware—has done to ensure IVAAP offers the best possible user experience and the fastest data visualization and aggregation. Interacting with a 100G+ 3D seismic volume in a web browser with great performance is now possible,” says Dr. Olivier Lhemann, founder and President of INT.
Read the press release on PRWeb >
For more information on INT’s newest platform, IVAAP, please visit www.int.com/products/ivaap/
Open Subsurface Data Universe™ and OSDU™ are trademarks of The Open Group.