Ever since the concept of web services first gained popularity, developers attempting to use these web services have faced two challenges: The first challenge is finding the right service to use; the second challenge is writing the code to call these services. The goal of this article is to describe how IVAAP uses HATEOAS hypermedia links to address both problems. We’ll also try to highlight other use cases benefiting from the concept of hypermedia applied to microservices.
A Brief Description of HATEOAS
Most microservices developed today (including IVAAP’s) use a REST API. REST stands for “REpresentational State Transfer.” It’s a term coined by Roy Fielding, who is also the inventor of “Hypermedia as the Engine of Application State,” or HATEOAS. It describes REST services that use hypermedia links to describe how they relate to other services.
For example, in IVAAP, the metadata of a seismic dataset is typically accessible through a URL such as this one:
https://…/ivaap/api/ds/geofiles/v1/sources/a8b05811-6409-43bb-8902-c9142ab48cff/seismic/cG9zZWlkb24gdmRzIG4gc2VneS9Qb3NlZGlvbiBkZXB0aC9wc2RuMTFfVGJzZG1GX2Z1bGxfd19BR0NfTm92MTFfdmVsNV9kZXB0aF8zMmJpdHMueGd5
Unlike the JSON content returned by a classic REST service, the JSON content returned by this IVAAP service contains more than just the requested metadata. It also contains a “links” JSON node that leads to additional information about this seismic dataset.
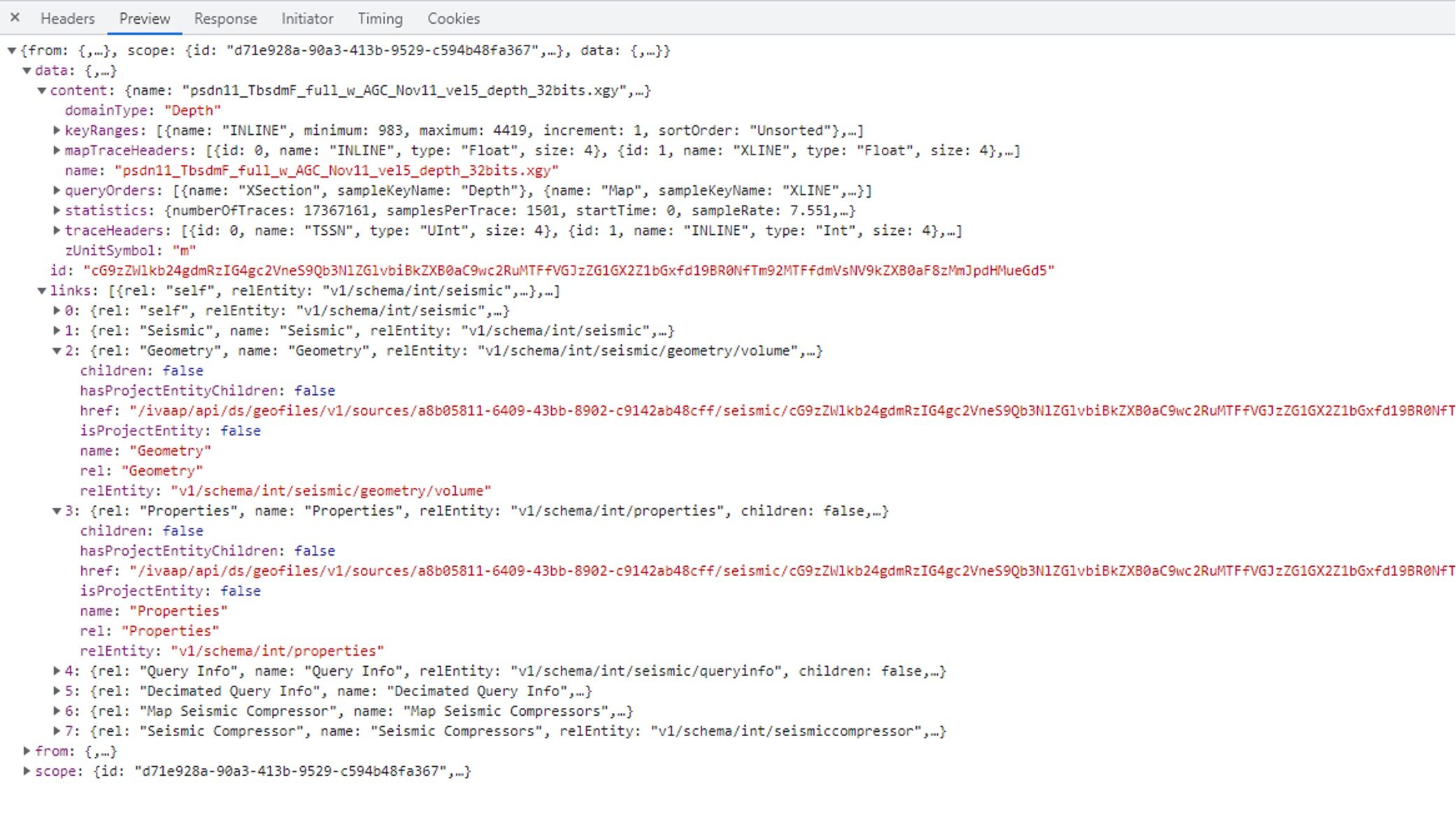 A sample JSON output for the IVAAP “seismic metadata” service, as shown in Google Chrome Developer Tools
A sample JSON output for the IVAAP “seismic metadata” service, as shown in Google Chrome Developer Tools
In the example above, there are multiple HATEOAS links. One of them is the “Geometry” link. The purpose of the seismic geometry service is to expose the shape of seismic surveys. The URL of this service is:
https://…/ivaap/api/ds/geofiles/v1/sources/a8b05811-6409-43bb-8902-c9142ab48cff/seismic/cG9zZWlkb24gdmRzIG4gc2VneS9Qb3NlZGlvbiBkZXB0aC9wc2RuMTFfVGJzZG1GX2Z1bGxfd19BR0NfTm92MTFfdmVsNV9kZXB0aF8zMmJpdHMueGd5/geometry
This Geometry service is meant to be used by applications showing seismic datasets on a map. An application leveraging HATEOAS links would typically examine the “links” returned by the “seismic metadata” service to retrieve the URL of the associated “geometry” service. An application not leveraging HATEOAS links would hardcode the logic that /geometry needs to be added to the URL of the “seismic metadata” service to get the same result.
Both approaches are valid, but the HATEOAS approach brings multiple benefits that we are going to detail.
The “Broken Link” Issue Applied to Data
If you surfed in the ’90s, you are certainly familiar with the concept of “broken links.” Back in those days, websites were made of pages maintained by hand, and text on these web pages was often peppered with underlined words (often colored in blue) leading to another page. If the target page was moved, the link would stop working and the web surfer would be greeted by an unhelpful 404 error instead.
The lesson from these early days is that web page URLs are anything but permanent. The initial idea behind HATEOAS links is that this lesson can be applied to web services, too. If an application uses a hard-coded service URL to read data, this application will immediately stop working if that web service is moved. If each microservice describes the URL of related microservices, then the application can just follow URLs instead of using hard-coded versions. The maintenance of URLs becomes a server concern, and no longer a service consumer concern.
The main issue with this concept is that its purported benefits are unproven in the real world. To prove the benefit of this “forward compatibility” approach, you’d have to observe the life-cycle of many microservices (and consumers of these microservices) over a long period of time to determine whether the use of HATEOAS links was worth it. Taking IVAAP as an example, even though the IVAAP microservices use HATEOAS links, changing the URL of an IVAAP REST API is a rare event. One of the reasons is that there is no way to enforce the use of these links on the service consumer side. HATEOAS doesn’t provide a guarantee that no consumer hard-coded any URL. It is even sometimes faster to use hard-coded URLs, for example, to restore dashboards.
The second issue is that the “broken link” issue is a narrow backward compatibility concern, focused on URL changes only. While services may move, their API might also change, and HATEOAS doesn’t provide a way to address the backward compatibility of service APIs.
Discoverability
While HATEOAS links may help address issues associated with changing URLs, HATEOAS links really shine when it comes to discoverability. A component like the IVAAP Data Backend has hundreds of microservices. It doesn’t matter if each one of these services is documented, just finding whether a service exists is a complex task. HATEOAS links clearly indicate all URLs related to the data being accessed, in a consistent manner.
IVAAP is a platform. It was designed so that INT customers can modify the user interface using the IVAAP Client SDK, and we strive to make it as easy as possible. HATEOAS links give contextual documentation of the services that are available for any server-side object that the UI is accessing. As a result, modifying the IVAAP UI doesn’t require client-side developers to discover the server-side REST API before getting started. Developers can be immediately productive.
Testing
Developing a web-based application like IVAAP has a bit of a chicken-and-egg problem. You need to start by developing the data services first, but you don’t really know how well they work until the UI consuming these services is complete.
To get ahead of the game, there are methods to unit test data services, but they are time-consuming to follow. Just building by hand the right URL to test takes time, especially with long URLs. And because data quality varies, bugs might be data-specific and you need to test a bunch of them to make sure your data services are rock solid.
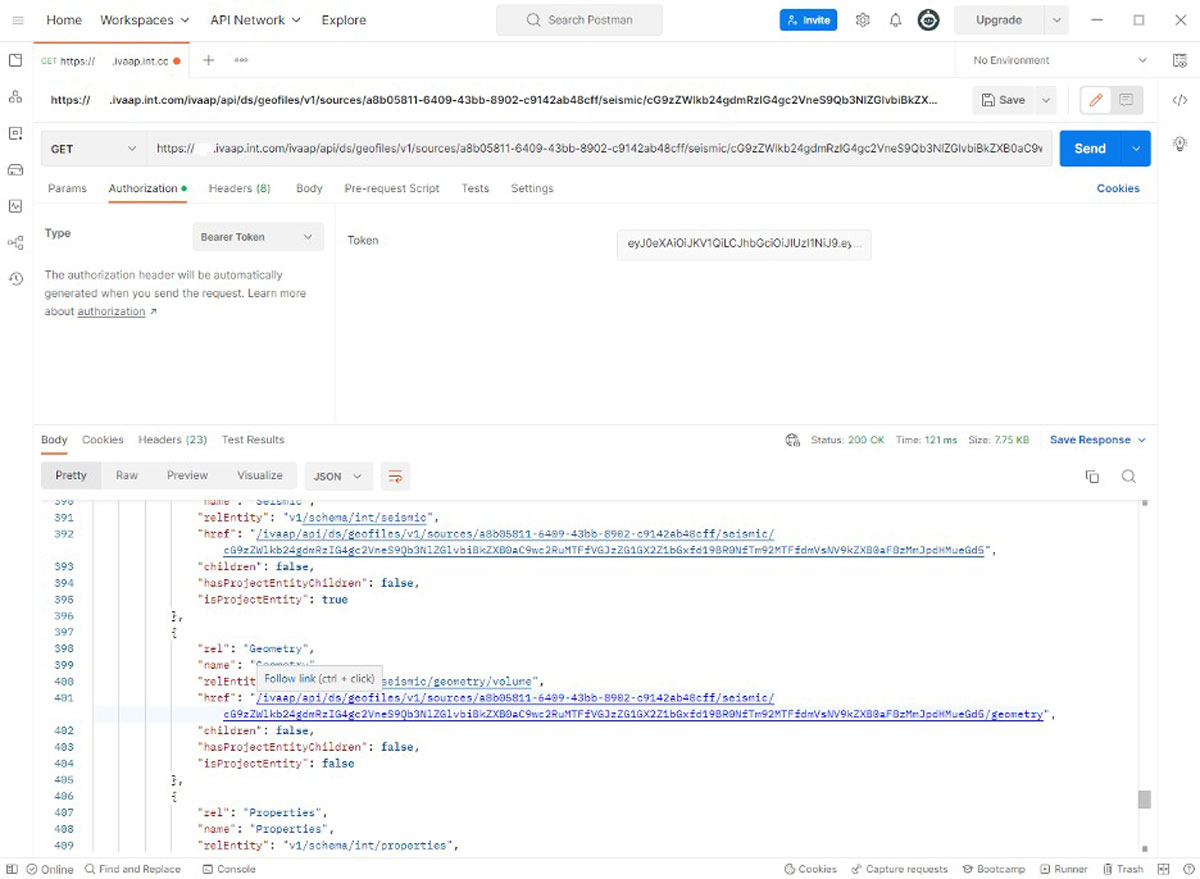
Following HATEOAS links with Postman.
A widely used tool to inspect and test web services is Postman. Postman “understands” HATEOAS links and testing your work just consists of following links within Postman, just like you would do with an HTML-based website.
The most common use case of the IVAAP Data Backend SDK is when INT customers write a connector that accesses a proprietary data source. The testing steps of such a connector are typically very fast because they don’t require the UI to be ready. Most bugs can be found immediately, just using Postman.
Going Beyond: Automatic UI Generation
Discoverability and testability are well-known benefits of including HATEOAS links in a REST API. IVAAP also uses HATEOAS links to generate part of its user interface. For example, the tree that is shown to users when they open a well is server-driven, not client-driven. The IVAAP UI parses the HATEOAS links and builds a tree of nodes based on them.
Not all wells have the same details of data. Some wells might only have a location, others might have a trajectory. The presence of relevant HATEOAS links is what gives the UI the information on which data is available for that well. The IVAAP UI doesn’t need to understand what a trajectory is to include a trajectory node under a well node. The tree is generated automatically from HATEOAS links.
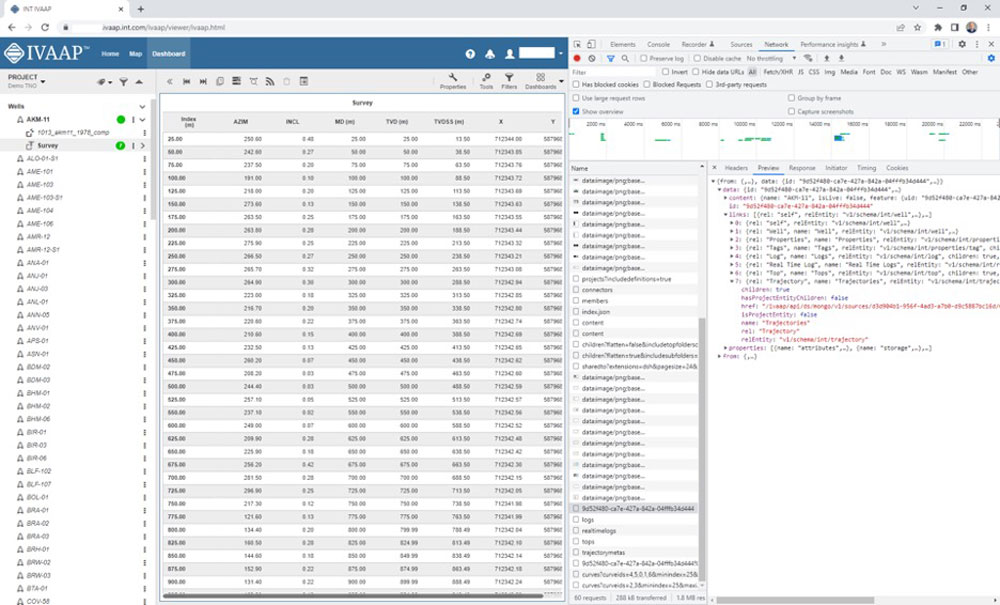
The nodes under the “AKM-11” well (left), as listed by the HATEOAS link for that well (right).
Not all HATEOAS links associated with an object are meant to be shown as nodes in the UI. By convention, only the HATEOAS links with the attribute “children” set to true should be shown. Customers who want to customize the nodes shown in the UI don’t need to write client-side code. They have complete control by just plugging their own code into the Data Backend.
The same technique is used to build the UI, allowing users to add datasets to their projects. The Data Backend advertises through HATEOAS links how data from a connector can be browsed, and the UI parses these HATEOAS links to build a matching user interface.
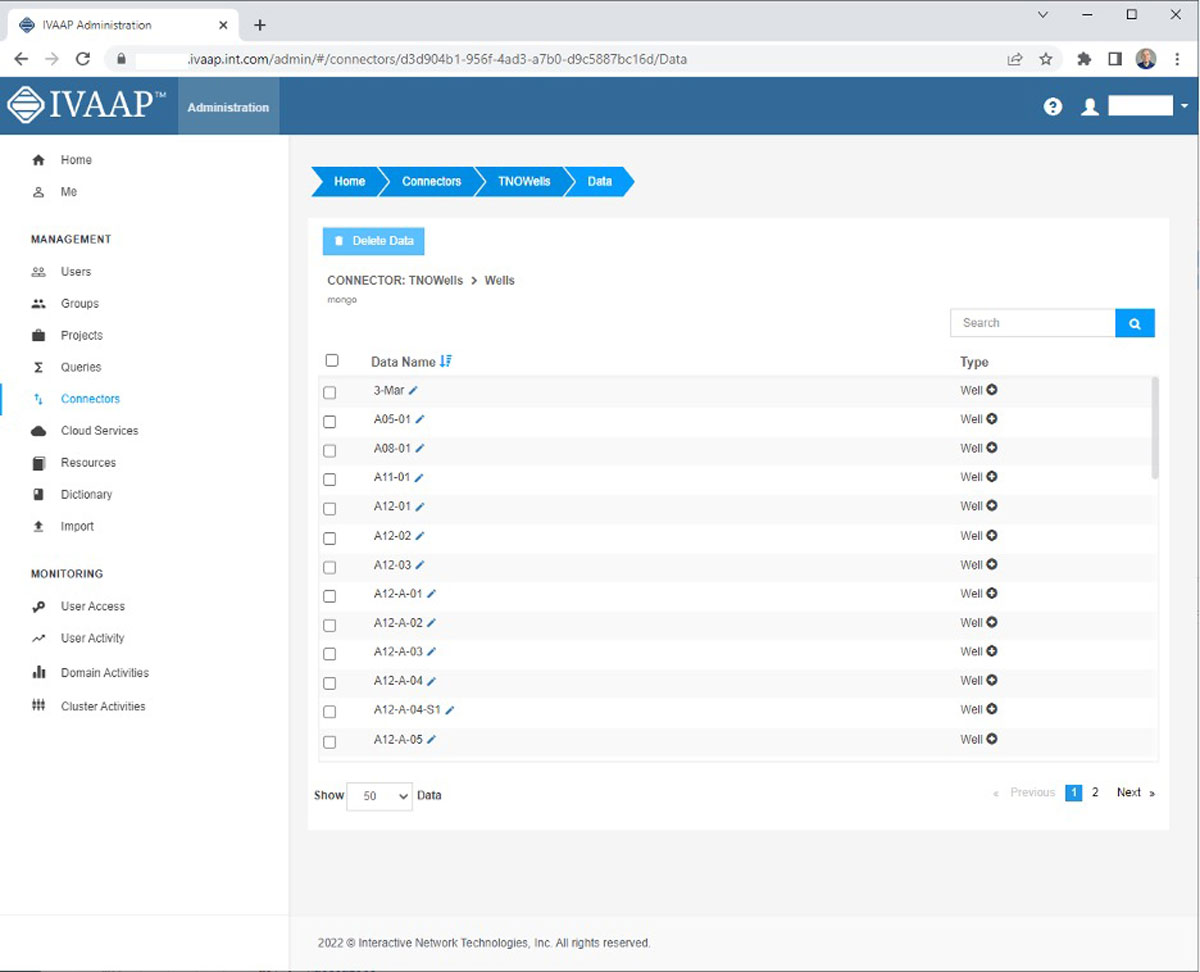
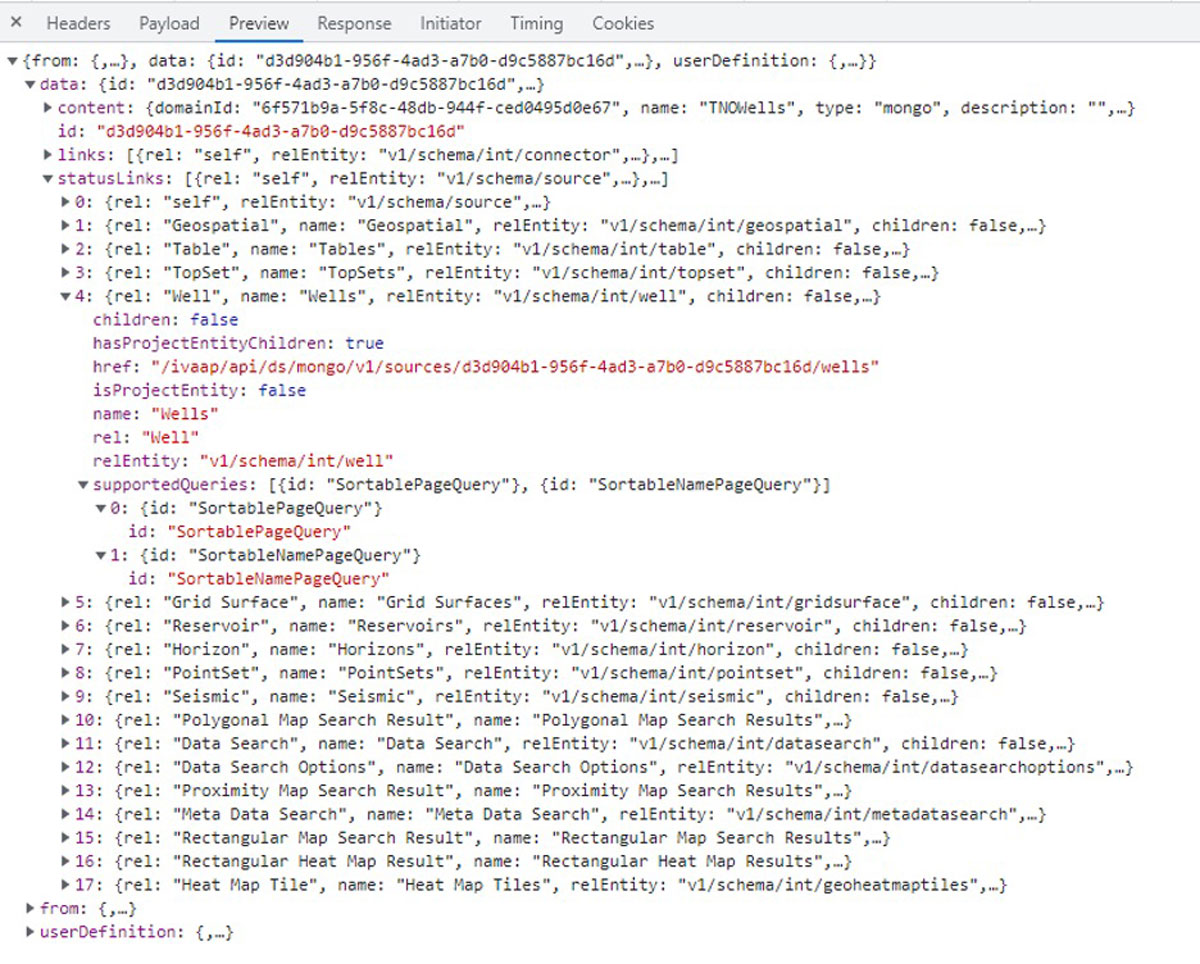
User interface generated when listing wells in a “mongo” connector.
Each data source has different capabilities, and this is reflected in the user interface. Some data sources might support search by name, paging, or sorting. For example, when search by name is supported on the server side, the IVAAP UI may propose a search box. IVAAP advertises querying capabilities to the user interface by including a “supportedQueries” attribute along its HATEOAS links.
A sample JSON output for the IVAAP “connector” service, as shown in Google Chrome Developer Tools.
Likewise, it is sometimes convenient to be able to edit the name of a dataset from the same user interface. Not all data sources support name editing, and it’s only when editing is supported by a connector that a relevant HATEOAS link should be included in the server responses.
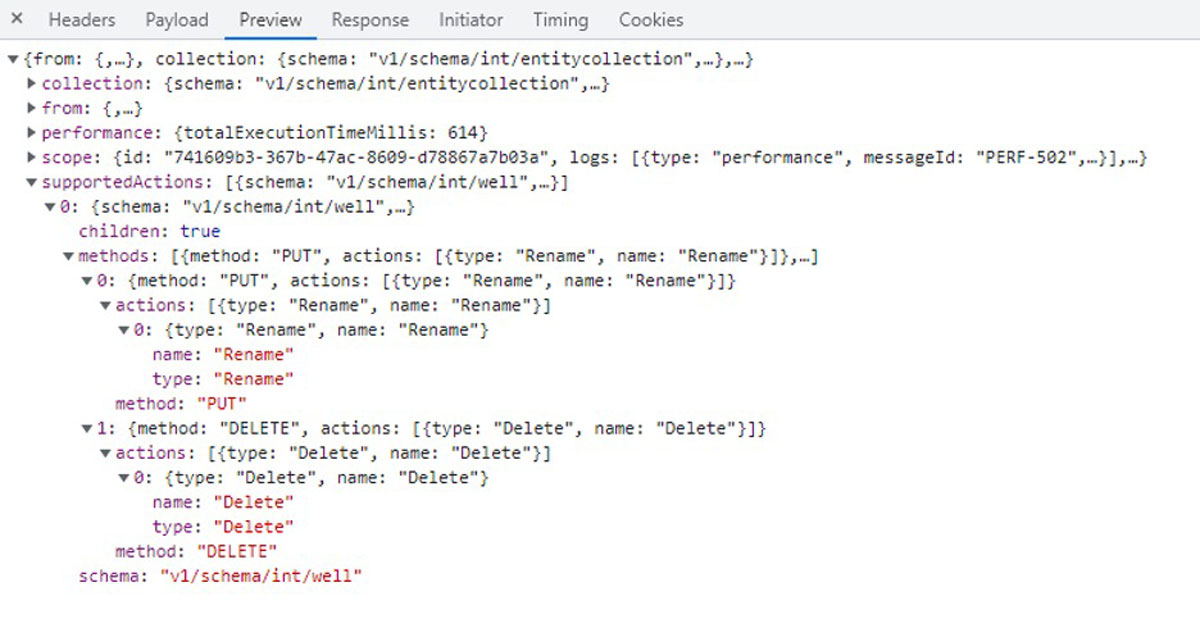
A sample JSON output for the IVAAP “connector” service, as shown in Google Chrome Developer Tools.
In the response above, not only the Data Backend advertises that data names can be edited, but it also indicates it supports data deletion.
This concept of automated UI generation using HATEOAS links is not a standard use. It requires the addition of attributes that are typically not seen in web services using HATEOAS links. They have powerful tools as they reduce the amount of work on the client side. Actually, the IVAAP REST API is designed to support more complex than the two use cases already mentioned.
A majority of the IVAAP REST services are either services returning a collection of meta-data, or services returning the meta-data of a single dataset. The JSON format of these two types of services is standardized across the IVAAP Data Backend. Because the services provide consistent JSON outputs, it is easy to write a generic UI that will browse through the entire tree of meta-data and even allow editing. In other words, you can write a basic IVAAP client from scratch without much effort on the UI side.
A completely automated UI would not be limited by the search and editing capabilities advertised in HATEOAS links. Each IVAAP REST service comes with its own documentation. This documentation is accessible in the OpenAPI 3.0 format using a standard mechanism.
In this mechanism, if the URL of the service listing wells in a MongoDB database is: https://…/ivaap/api/ds/mongo/v1/sources/a8b05811-6409-43bb-8902-c9142ab48cff/wells/, the URL of its matching OpenAPI documentation would be: https://…/ivaap/api/ds/mongo/v1/sources/a8b05811-6409-43bb-8902-c9142ab48cff/wells/openapispecs
A completely automated UI could expose the search parameters described in this documentation, a bit like SwaggerEditor does. This wouldn’t be limited to search, the same principle can be applied to updating and deleting data.
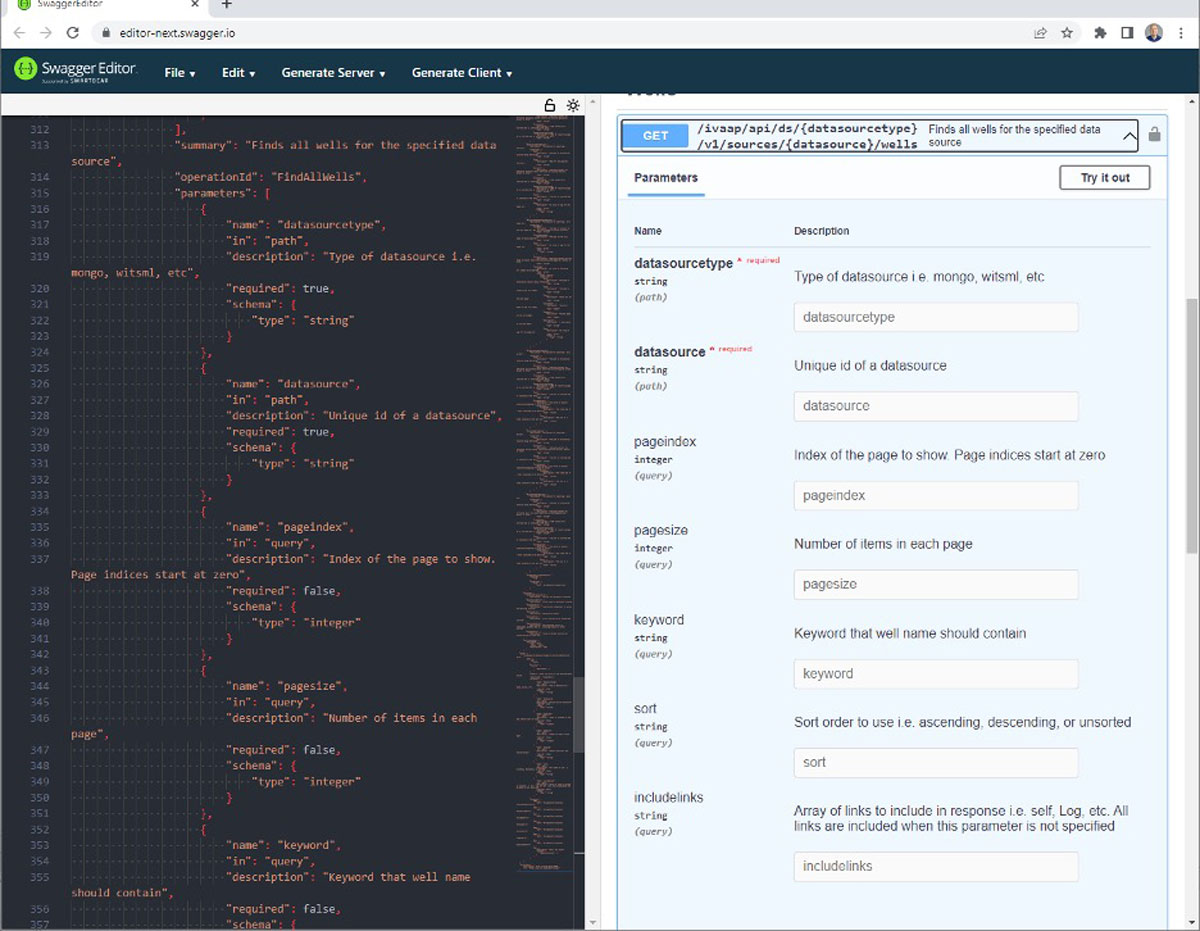
A form generated automatically by SwaggerEditor from the OpenAPI specification of the wells service.
Going Beyond: Batch Support
Another feature enabled by HATEOAS links is the ability to fetch multiple aspects of a dataset in one HTTP call.
Microservices work best when they do only one thing at a time, but this means the IVAAP client needs to make multiple calls to the Data Backend to restore a dashboard. Currently, Google Chrome only allows up to 6 concurrent HTTP connections per host, sometimes forcing the client to “wait” for the availability of connections. This has a direct impact on the user experience.
To help with this, the IVAAP Data Backend provides a so-called “Batch” REST API to retrieve the content behind multiple URLs in one go. Other servers also have this feature, but what’s different about IVAAP’s Batch API is that it allows developers to leverage HATEOAS links.
For example, if you are building a data map and need to retrieve the metadata of a seismic dataset along with its outline, you would specify to the Batch REST API that you need to retrieve the content behind https://…/ivaap/api/ds/geofiles/v1/sources/a8b05811-6409-43bb-8902-c9142ab48cff/seismic/cG9zZWlkb24gdmRzIG4gc2VneS9Qb3NlZGlvbiBkZXB0aC9wc2RuMTFfVGJzZG1GX2Z1bGxfd19BR0NfTm92MTFfdmVsNV9kZXB0aF8zMmJpdHMueGd5 as well as the content behind the associated “Geometry” HATEOAS link. This method of fetching multiple aspects of a dataset at once is much more expressive than passing multiple URLs to the Batch REST API.
Something that should be noted when it comes to performance is that we made the HATEOAS links an optional feature of IVAAP. Consumers of the IVAAP Data Backend API who don’t use these links can opt to reduce the size of the JSON payload between the client and the server. The default behavior of the Data Backend is to include HATEOAS links, but the collection services can be called in a way that excludes these links completely or only includes specific, named links.
Conclusion
HATEOAS links have been a part of the IVAAP Data Backend since day one. Over time, we found that they pack much more functionality than we initially thought. All these features have a common goal: facilitating the work of the UI developers and accelerating the delivery of software. While I used examples from IVAAP, the ideas in this article can easily be applied to your own data backend.
For more information or for a free demo of IVAAP, visit int.com/products/ivaap/.