
A Closer Look at IVAAP

In our latest Tech Talk, E&P Visualization in the Cloud, we featured IVAAP, our cloud-enabled visualization and analytics development platform. We showed how it can be used to monitor and analyze well data as a critical part of your digital transformation.
Thierry Danard, our VP of Core Platform Technologies, presented some of the technical aspects of IVAAP, so we asked him a few questions after the talk to dig a bit deeper:
> Hi, Thierry! We already know that you are the brains behind INTViewer, so which part of IVAAP are you responsible for?
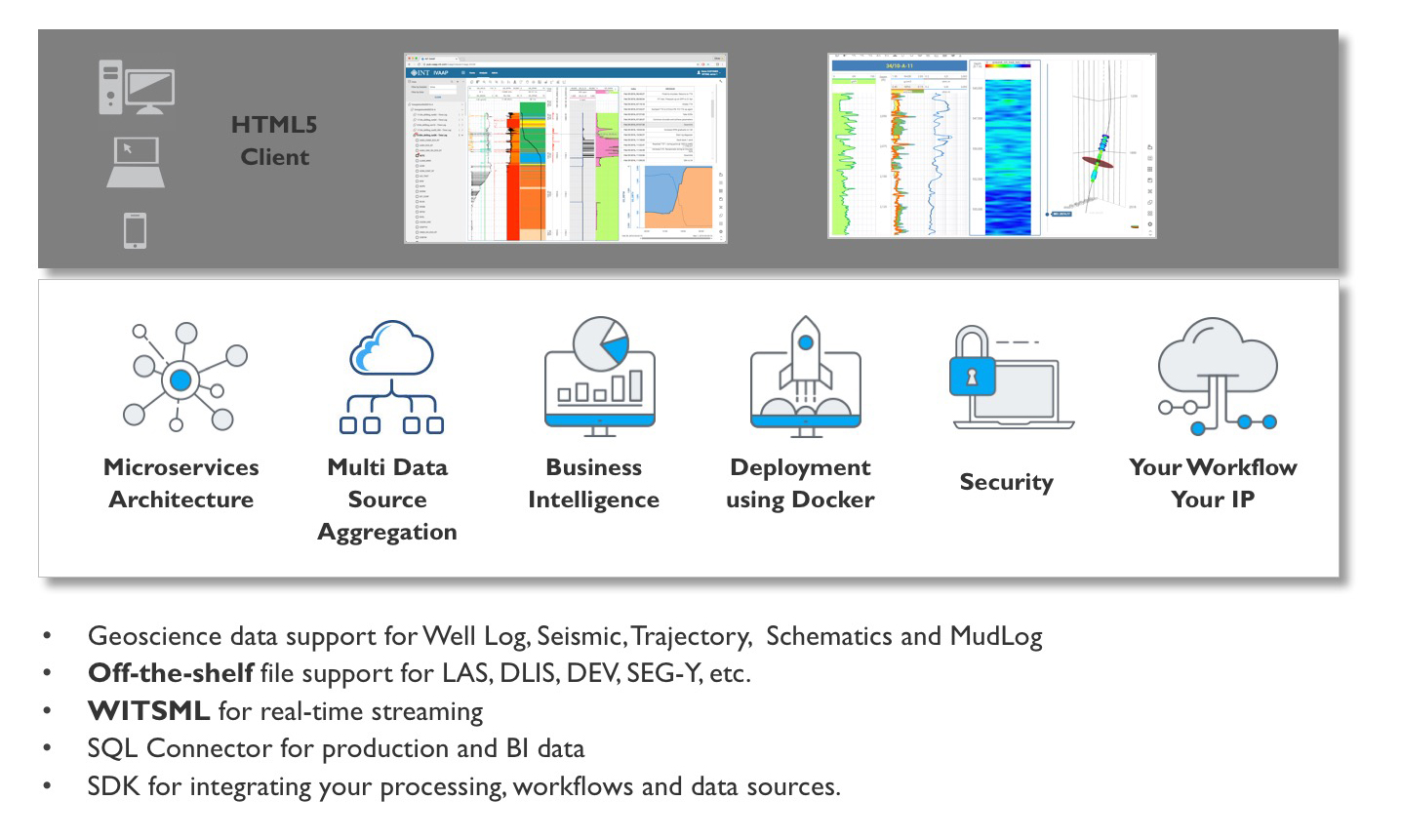
I mostly work on the “P” part of IVAAP, the “platform.” IVAAP can be customized fully, both on the browser side and on the backend side. I focus on the backend side, meaning the microservices on the data side.
> What makes the IVAAP platform unique?
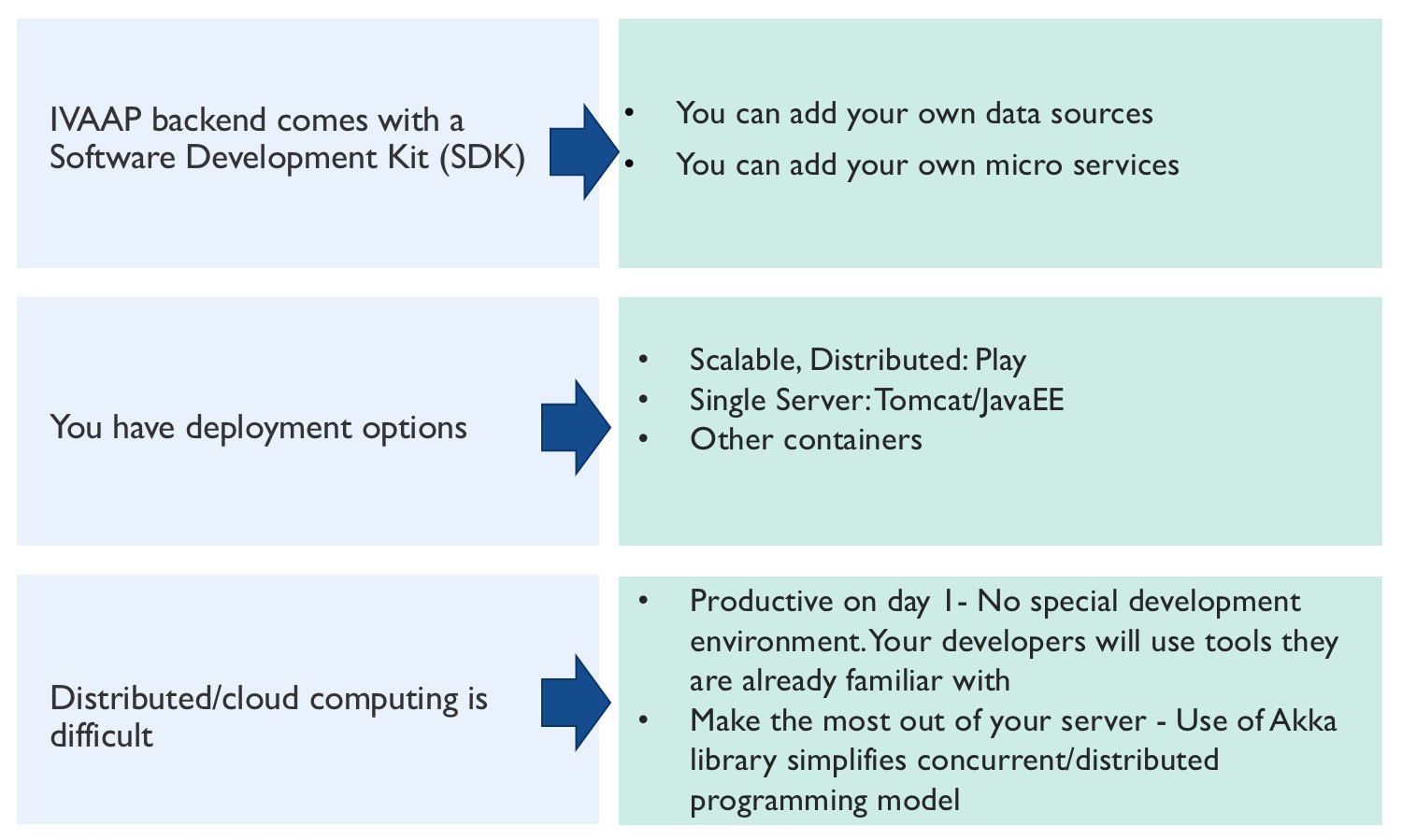
IVAAP comes with a Software Development Kit (SDK) so geoscience developers can tailor our solution to their needs. Developing solutions for the cloud is hard. We want to facilitate the work of these developers. The SDK is designed to ease the challenges developers face when developing distributed solutions.
But developers are not the only customers of IVAAP within IT. Deploying cloud solutions is also hard, and infrastructure folks want options when it comes to deployment. We made the IVAAP platform container-agnostic so that it can be deployed in a highly distributed environment or using standalone servers without changes: This is the same microservice code running.
IVAAP is unique because it bridges the gap between the business and IT: It provides a common platform that both sides can embrace, not just end-users.
> Can you give us examples of containers that IVAAP works on?
The most widely used container for the IVAAP backend is Play. This is a high-velocity web framework designed to run on multiple machines, in a distributed fashion.
Another one is Apache Tomcat, the most widely used standalone Java application server. Other well-known JavaEE application servers are Oracle Glassfish and WebLogic.
> Why might a developer choose Tomcat over Play?
Not every customer has a network of machines to dedicate to well monitoring or analysis. Depending on what you use IVAAP for, you might not need distributed processing.
But developers also benefit. Developers can use the Integrated Development Environment (IDE) that they already use; it already works with Tomcat. No need to use a special environment, no need to install special plugins or to configure several servers. Developers can be productive from day one. The promise of IVAAP is to accelerate the delivery of geoscience, drilling and production cloud-enabled solutions. You can’t accelerate these deliveries unless your developers are productive.
> How does the SDK help developers create distributed microservices?
The IVAAP backend API makes a large use of the Akka library. Akka is a toolkit for building highly concurrent, distributed applications. The core Java programming model makes it very difficult for cloud developers to implement distributed processing. The Akka library addresses this concern with its simple model based on actors and messages.
Akka and Play are designed to work together. When Akka code is deployed in Play, you can sustain heavy loads. For example, the Akka actor system might decide to delegate individual processing units to one or several machines. This is virtually transparent to the developer as this is a behavior that depends on the state of each server.
> How does the SDK help developers create efficient microservices?
The API of the SDK is designed from the ground up to favor asynchronous execution over synchronous execution.
Synchronous code tends to reserve lots of resources just to wait for an answer. Asynchronous code doesn’t reserve these resources while a long processing task is being performed. Less CPU and less memory usage means more processing power for each deployed server, allowing your solution to perform under heavy loads.
> What’s coming next for the IVAAP backend?
Now that we made it easy to add new data sources and new microservices, we are adding connectivity to even more data repositories, such as OSISoft PI, Procount, or Peloton. This is a typical use case of the backend API. We have cleanly separated the microservices and data access parts. Now it’s just a matter of plugging additional data sources.
Stay tuned for more interviews with our developers! In the meantime, click here to learn more about IVAAP.